I've realised that there are text transformations I can do in markdown that often aren't possible in rich text.
E.g. from
[foo bar](https://example.com/)
to
foo [bar](https://example.com/)
Rich text usually forces me to remove the old link then highlight the new range.
miniblog.
Related Posts
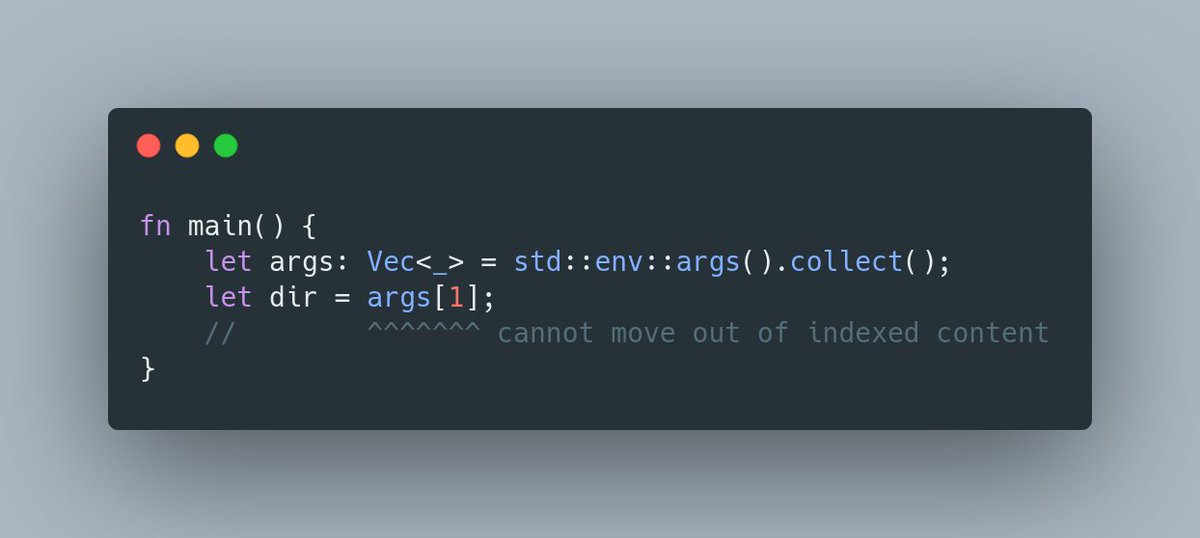
Rust gotcha I haven't seen before: you can't move out of a vec by index, even if you own the vec.
This is because it'd leave the vec in a bad state: you need .remove() or .pop() instead.
If function f1 is unused, and f2 is only called from f1, Rust complains that both f1 and f2 are unused.
I find this confusing: it's useful to know that I can remove both functions, but removing f2 alone gives a compile error.
Not sure what the best tradeoff is though.
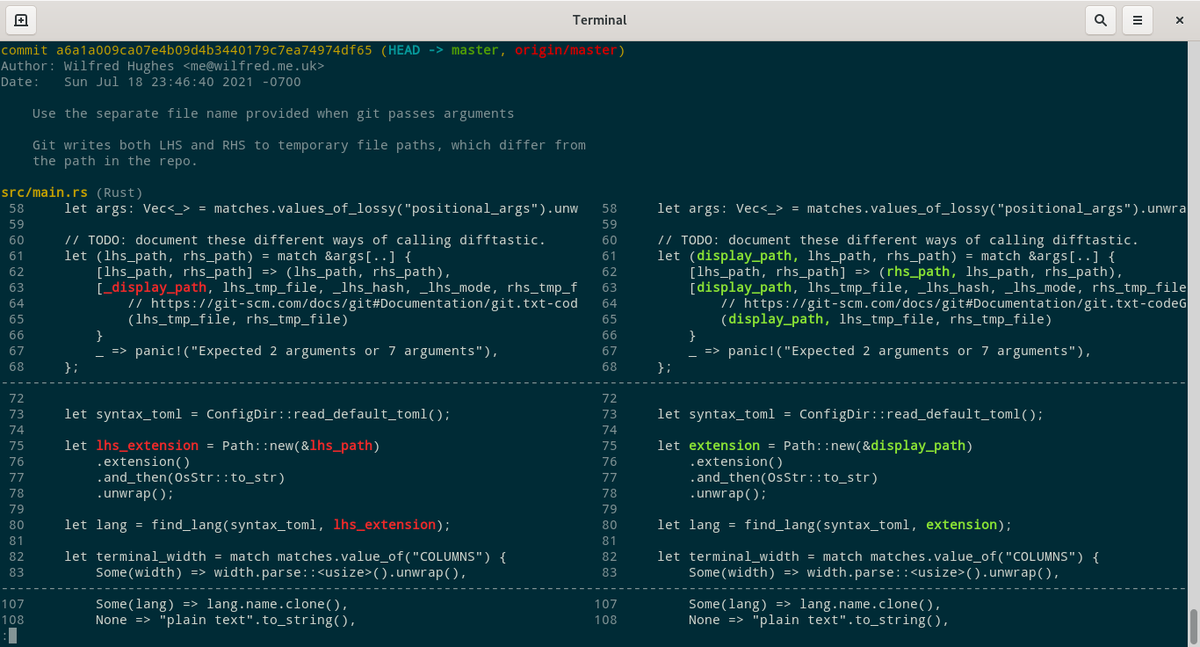
It's now possible to use difftastic for all your git diffing operations! I'm using `git log -p` in this screenshot.
(It crashes horribly if you add/remove whole files, or modify binary files, but it's really nice to dogfood and spot issues!)