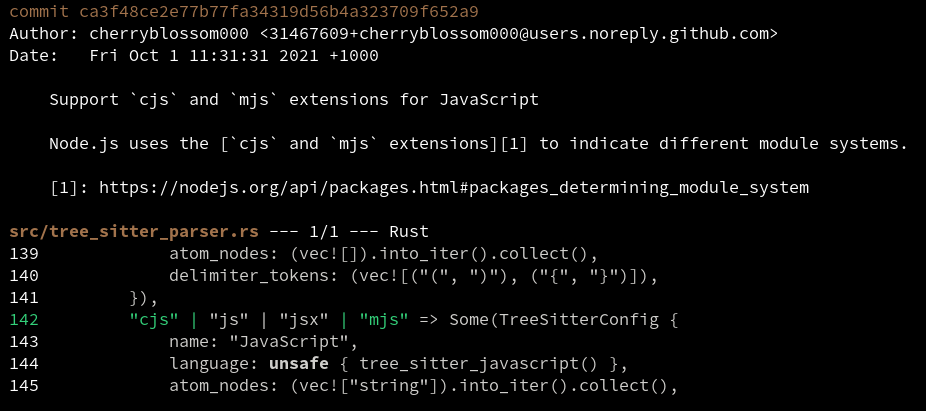
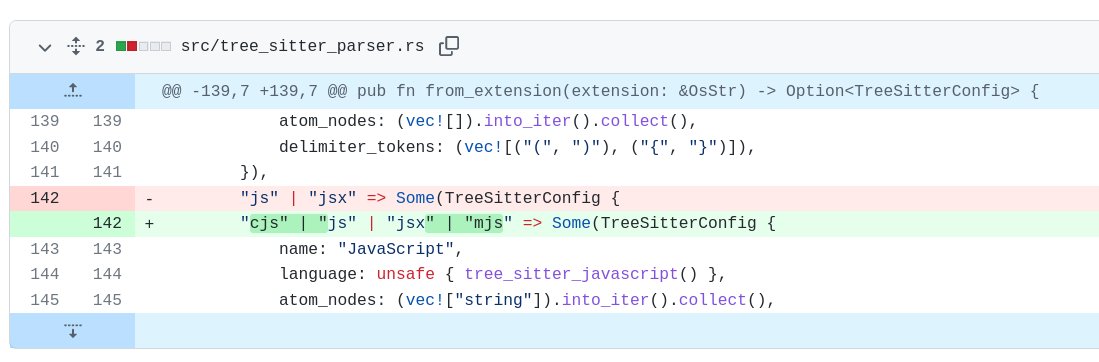
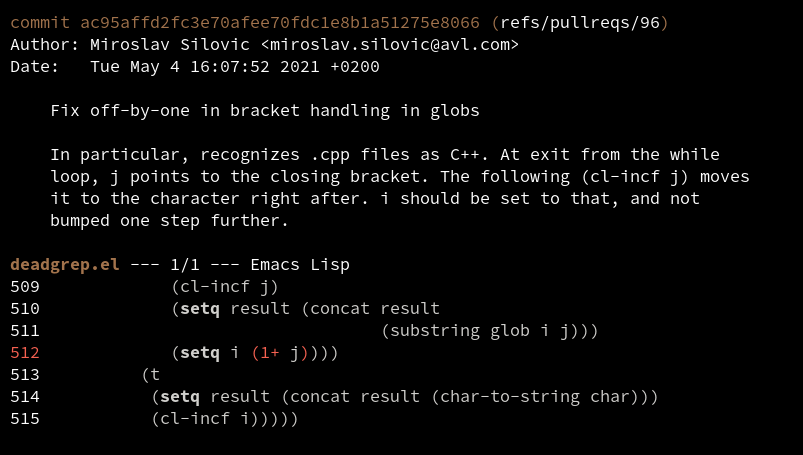
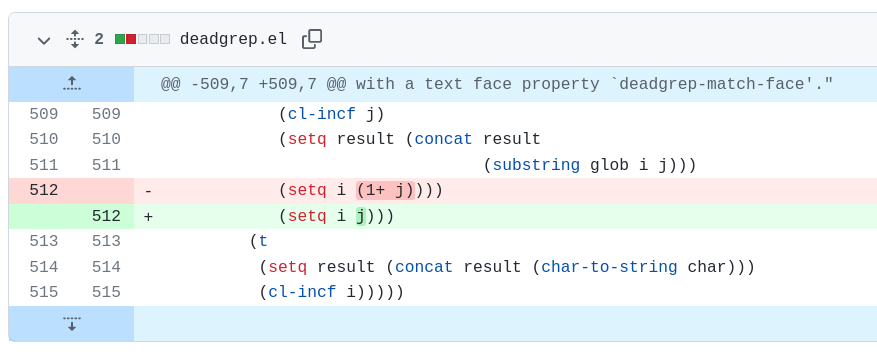
I've started seeing 'ort' merges in my git operations, which can apparently be hundreds of times faster than the previous merge algorithms: https://www.phoronix.com/scan.php?page=news_item&px=Git-2.33-Released
miniblog.
I've documented several additional interesting challenges for syntactic diffing: meaningful comparisons of large string literals, understanding blank line changes, and autoformatters adding minor punctuation!
Difftastic understands syntactic boundaries. I keep spotting cases in other diff tools where textual diffing can't show the structure.
A nice side effect of regular profiling: you know which parts of your code are cold.
For example, difftastic's display logic is very cold, so I can do additional linear scans to align content without perf worries!
There seem to be three ways to get a fix or feature added to an OSS project:
1: Contribute enthusiasm and camaraderie
2: Contribute and discuss patches
3: Contribute money
The amount required of each hugely depends on the work required.
Debuggers actually set breakpoints after the function prologue, but reliably identifying the prologue across compilers and optimisation levels is hard!
Difftastic 0.14 is out! https://crates.io/crates/difftastic
In this release:
* Language detection is much smarter, even understanding things like `#!/usr/bin/env python`
* Better Windows support
* Several crashes have been fixed
Too many languages introduce themselves as e.g. "Foo is a statically typed functional language", focusing on the basic characteristics.
I'd rather learn why Foo is special. What is Foo great for? Get me excited about what I could do with it!
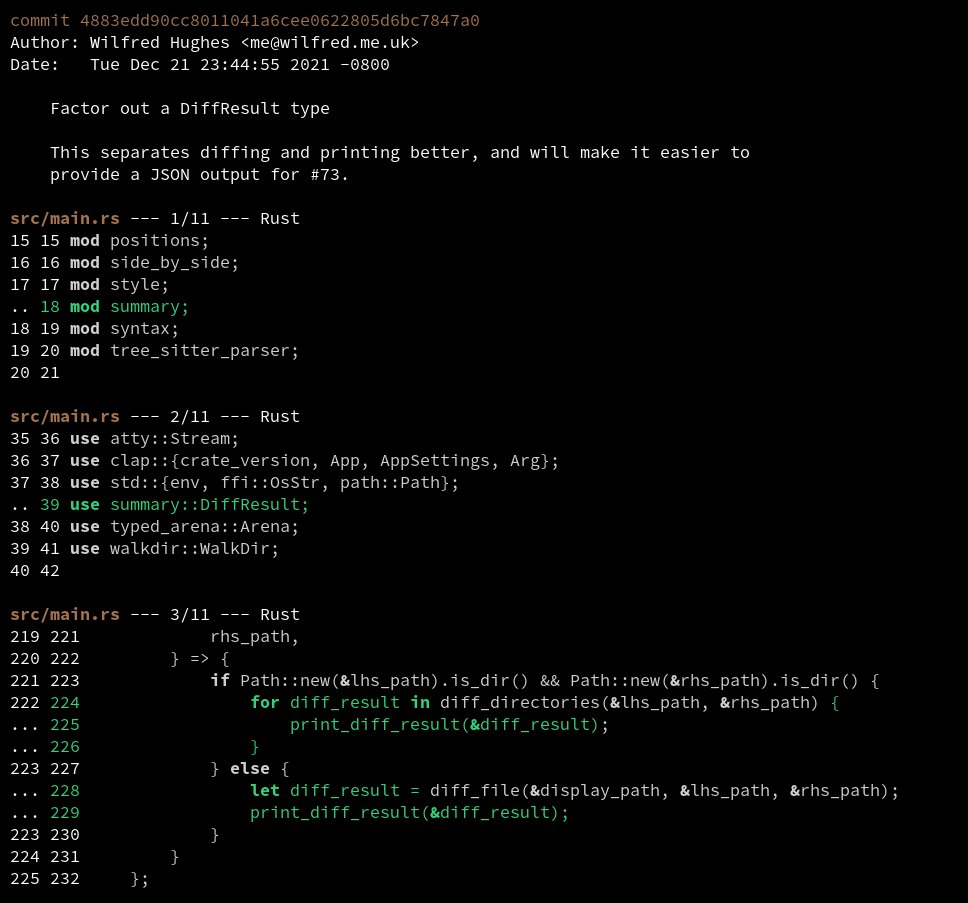
Reporting a type error is fairly straightforward: making a good suggestion of how to fix it is much harder. I was really impressed with rustc's handling of Path printing here.
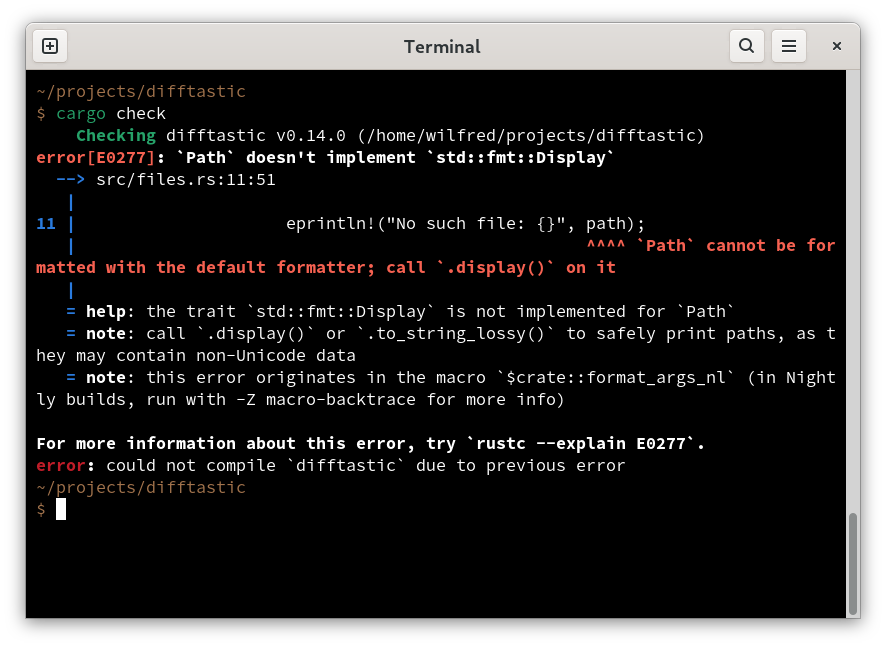
Cunning trick to ease upgrades in Rust. Each semver upgrade is a distinct type, but a library can depend on an older version of itself and preserve the types!
Prolog has a really unusual comparison syntax: it uses =< for less than or equal, unlike most languages which use <=.
Elixir has a canonical tree-sitter parser! https://github.com/elixir-lang/tree-sitter-elixir
This is the first 'official' tree-sitter parser for a PL I've seen.
The PHP 1.0 announcement has aged pretty well! Rasmus focuses on simplicity, how little you need to get started, and the things you can build.
This convenience and pragmatism has been a major factor in PHP's success.
ASCII strings are so convenient. Byte length and character (grapheme) length are the same, and display length is simple too (tabs are the main fiddly bit).
As soon as you have Unicode, you need to distinguish these and use non-trivial libraries!
An introduction to polyhedral compilation, with a worked example showing how you compute relevant linear transforms: https://www.youtube.com/watch?v=iAF-orse4hE
Showing 1-15 of 345 posts