In LSP, a position is represented as a line number and a column offset (in Unicode code units): https://microsoft.github.io/language-server-protocol/specifications/lsp/3.17/specification/#position
This is pretty elegant. You'll get the correct line regardless of encoding bugs, and the editor already knows the line number so it's cheap to compute.
miniblog.
Related Posts
TIL Rust has an ambiguity `if Foo {}` -- is `Foo` a value of type bool, or a struct?
Rust solves this by defining a grammar production 'any expression except struct literals' and using it in this position.
I'm a huge fan of Swift's 'Error Handling Rationale' design document: https://github.com/swiftlang/swift/blob/9315673c003875158852579bd1f33480cdec5461/docs/ErrorHandlingRationale.md#fundamentals
It carefully defines terminology and compares with other languages, so you can understand Swift's position and preference in the design space.
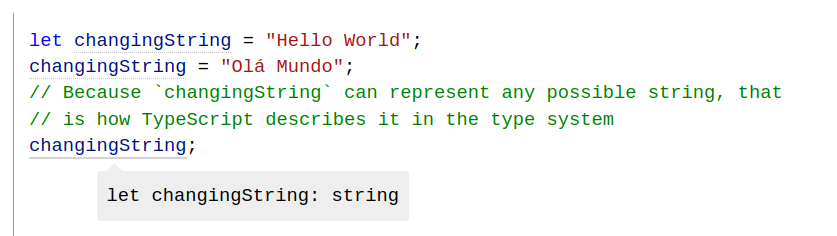
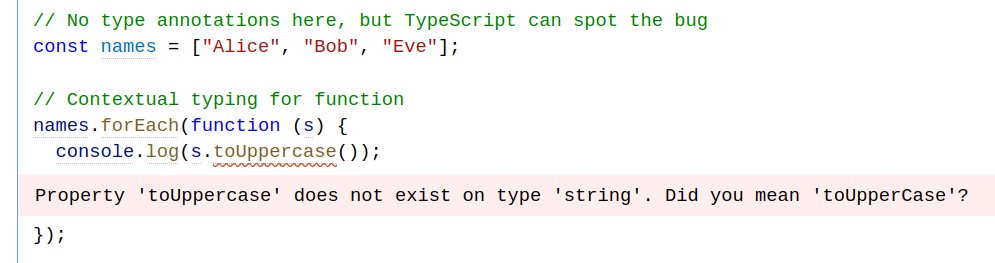
The TypeScript docs have IDE-like hover types on all the examples, which is really impressive.
I also like how the second example always shows the type of the relevant part, regardless of mouse position. It's clear and mobile friendly.
Screenshot from https://www.typescriptlang.org/docs/handbook/2/everyday-types.html#literal-types