I've heard of a 'burger menu' when a button has three horizontal lines on it, but today I heard 'kebab button'. This is similar, a button with '···'. Clearly UI designers are hungry.
I've heard of a 'burger menu' when a button has three horizontal lines on it, but today I heard 'kebab button'. This is similar, a button with '···'. Clearly UI designers are hungry.
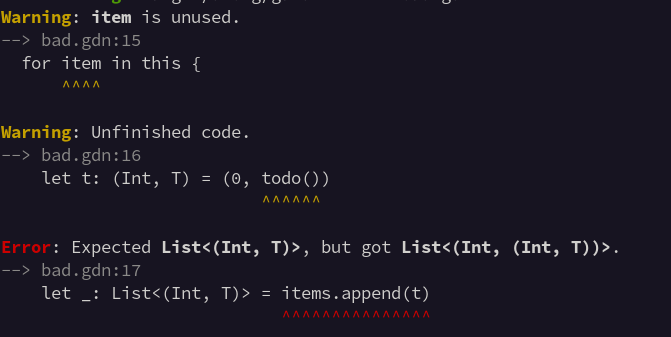
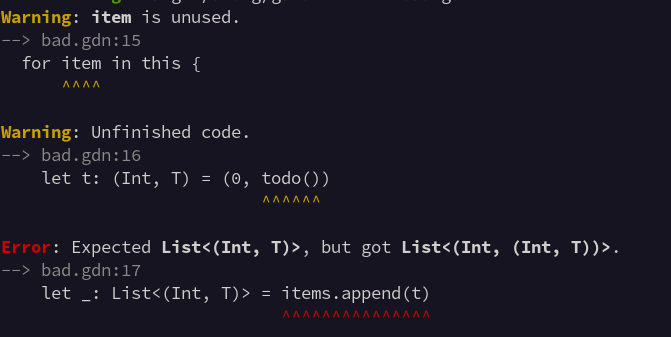
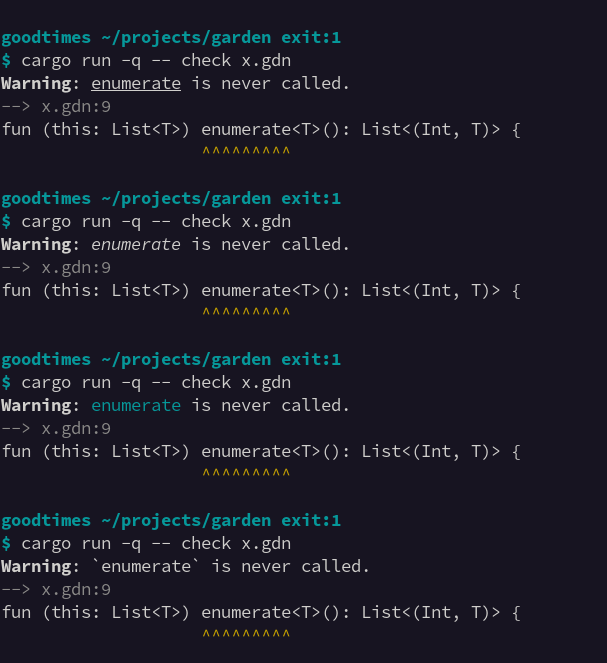
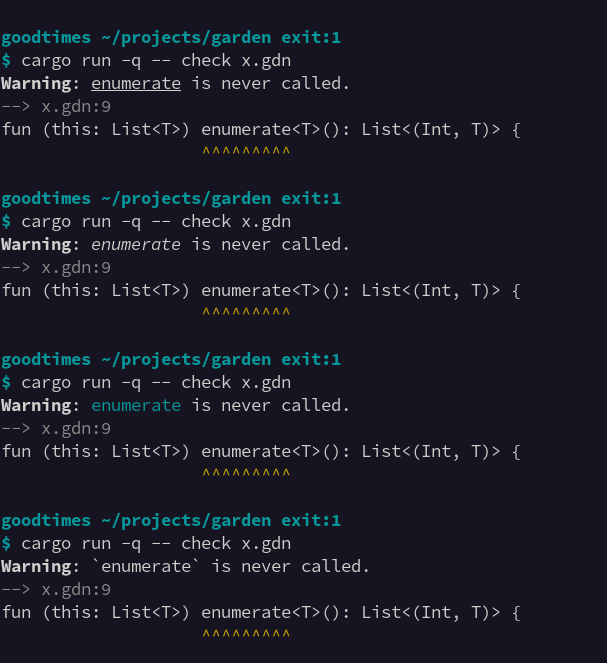
Doing another iteration on my diagnostics display. I'm reasonably happy with the bold highlighting within the error message.
I'm not sure about the colour on Warning and Error though. It gives the output some visual structure, but arguably the message itself is more important.
I hear people say that Go is often hard to search online (hence sometimes "Golang"), but the vast majority of language names are common words. Names with punctuation (C++, C#) are hard too.
Is this a big problem in practice? "Perl" isn't a dictionary word, but it's an exception.
I've released difftastic 0.63! In this release:
* Better parsing of Elixir, LaTeX, Make, Nix, Rust and YAML
* Better detecting of text encoding, especially on Windows
* Prebuilt musl binaries, so you can run released binaries on older systems!
I made some changes to a node express project that I haven't touched in almost five years. I was pleasantly surprised that I only needed to update one dependency to get it working again!
(It was sqlite3, which is a native dependency using node-gyp.)
I'm experimenting with jj this weekend. It seems pretty nice so far, but the mental model is pretty different from git.
For example, there's no `checkout` command. You do `jj new ABC` to switch to a commit, which creates a new empty commit on top of ABC.
I've just squeezed another 5% of performance out of difftastic by finding a few HashSet values that weren't FxHashSet.
I do wonder whether hash DoS resistance is a good default. Sure, Rust programs are often pretty fast anyway, but it feels like a different threat model to the rest of Rust.
I'm experimenting with live-evaluating tests in my programming language project.
It's relatively fiddly to hook up a UI for this, but it saves a precious keystroke to run the tests! I'm hoping that it results in more, better tests due to the convenience.
I'm experimenting with Atuin for searching my terminal history: https://atuin.sh/
Previously I'd just used fzf to find items, which does work nicely. Occasionally I *really* want to search "commands which were run in this directory" though, which Atuin offers.
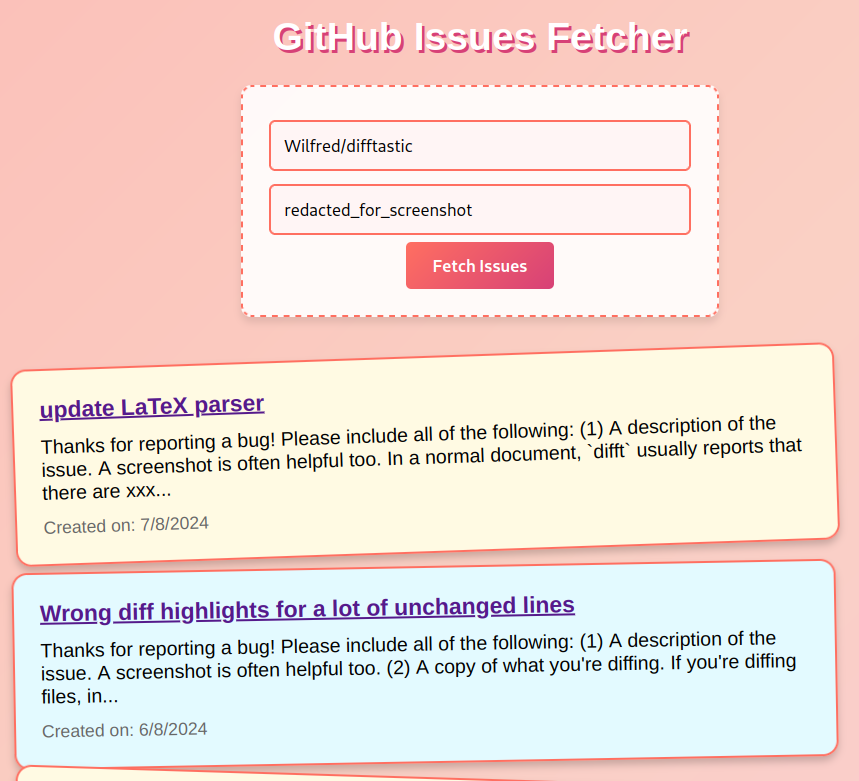
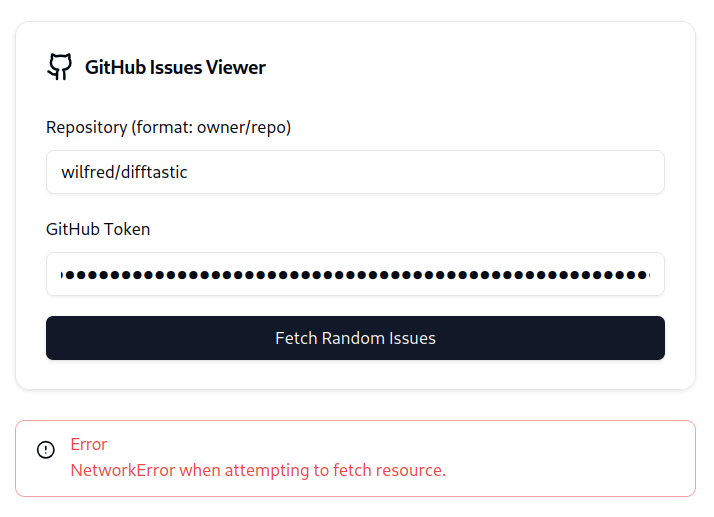
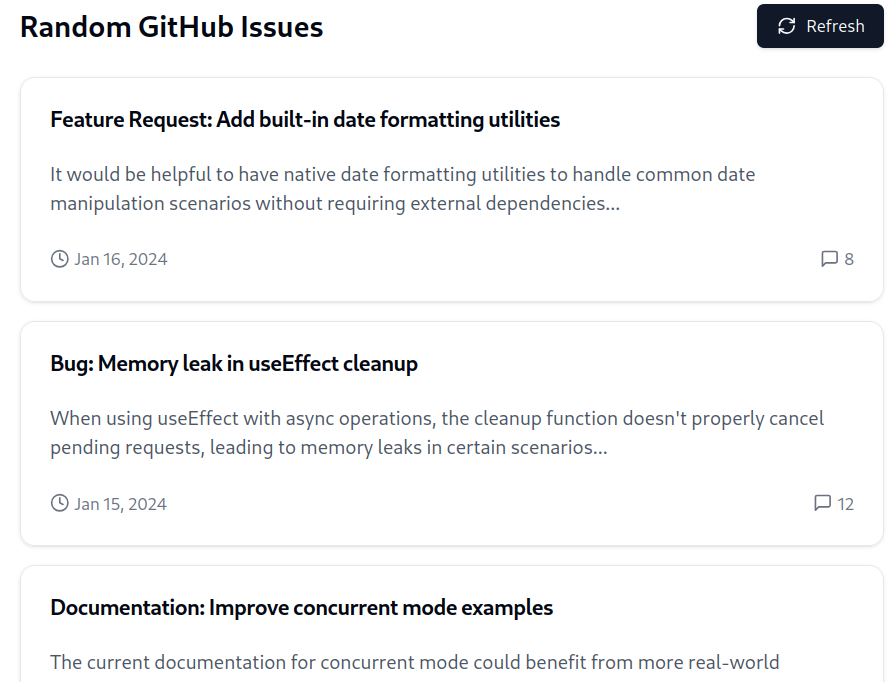
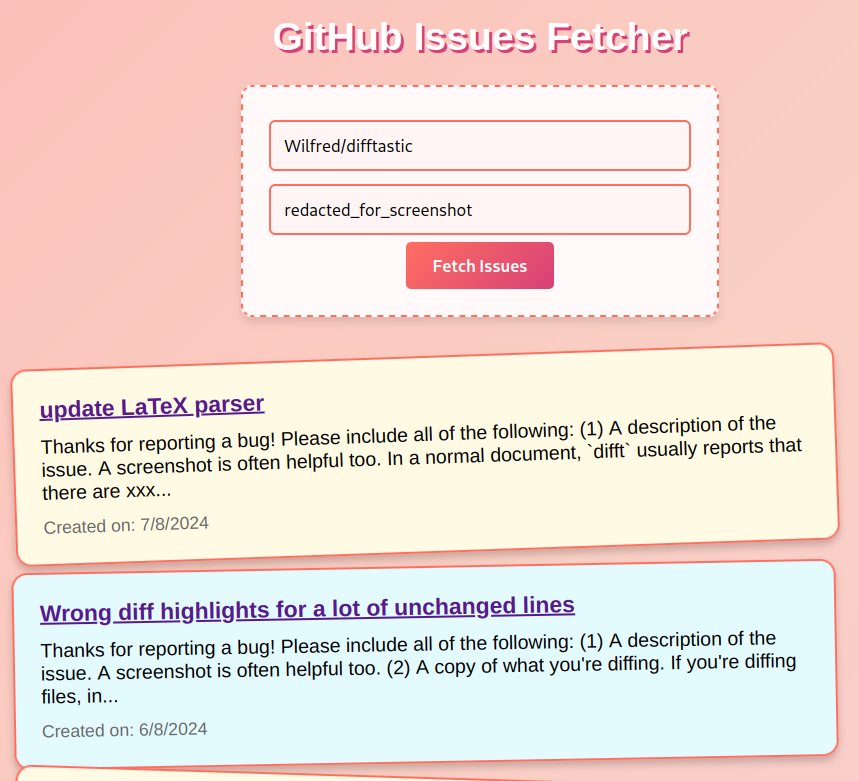
I have a bunch of open tasks on my GH repos, so I tried asking ChatGPT and Claude to write a card-based web UI that showed some random open issues.
ChatGPT gave me something that worked, but the Claude mock-ups look better (and render inline!).