3 stages of code reading: understanding the flow, understanding the details, then assaulting the code until you're persuaded it's correct.
miniblog.
Related Posts
1523
Today I learnt that Racket *intentionally* doesn't have a traditional REPL workflow. The authors were concerned about students not understanding the state between the current session and the code on disk.
(Arguably Jupyter has some of these features now.)
My understanding of Rust Foundation and Rust Project has definitely improved following today's talk.
Rust Foundation: Handles financial, legal and bureaucratic stuff. Requires a supermajority of votes from both sponsors and the Rust Project.
Rust Project: Focuses on building.
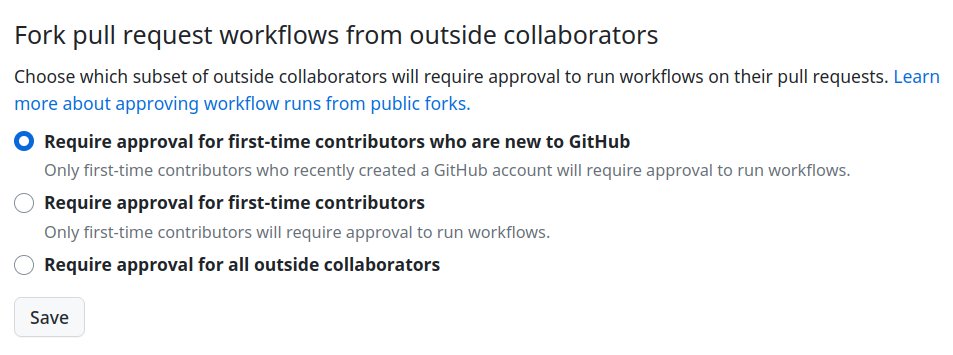
Ooh, I've just discovered that you can enable actions on GitHub pull requests by default! This is the actions settings page.
My understanding is that GitHub introduced these limits to prevent people trying to run cryptominers on GitHub actions. Sounds like GitHub has largely fixed it.