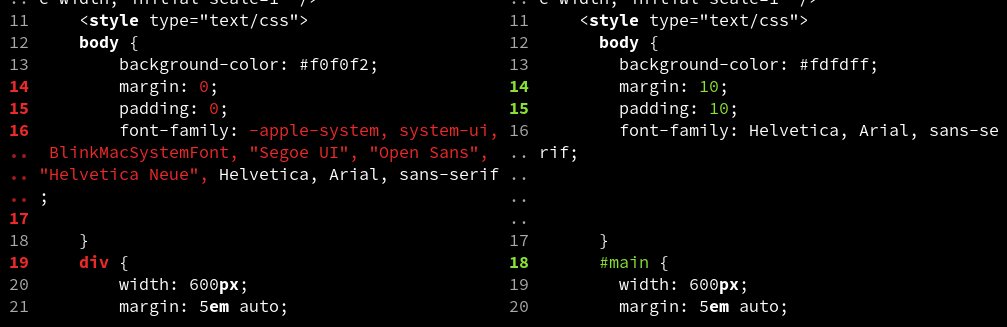
The next version of difftastic will support parsing CSS and JS syntax inside HTML! This makes a huge difference to HTML files.
This support for tree-sitter sub-parsers was contributed by Sesse :)
Writing a programming language? Challenge the design status quo:
Zig has moved to a compiler bootstrap approach that uses webassembly:
https://ziglang.org/news/goodbye-cpp/
They check in the wasm artifact and provide their own wasm compiler. wasm is the most portable backend supported by LLVM.
OCaml does something similar! It includes a minimal VM.
Reading the beta 4 release notes for Haiku R1, it's striking how much work it is to support modern WiFi protocols:
https://www.haiku-os.org/get-haiku/r1beta4/release-notes/
Previously, 802.11ac was only supported on Linux and OpenBSD! (Ignoring proprietary operating systems)
Is there any way to filter out toots that aren't in languages you understand?
I see translation offered on some toots, so presumably there's at least some language detection.
Wow, Android is throwing significant weight behind RISC-V:
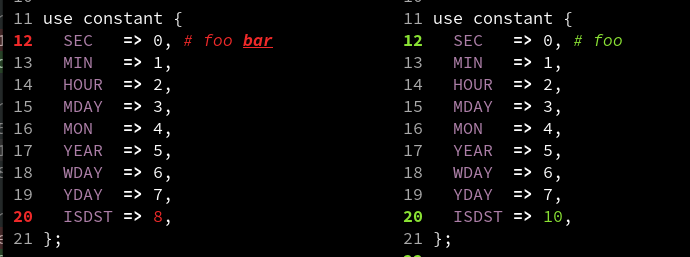
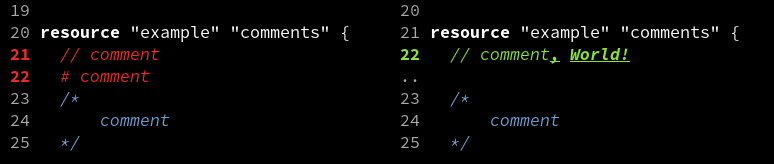
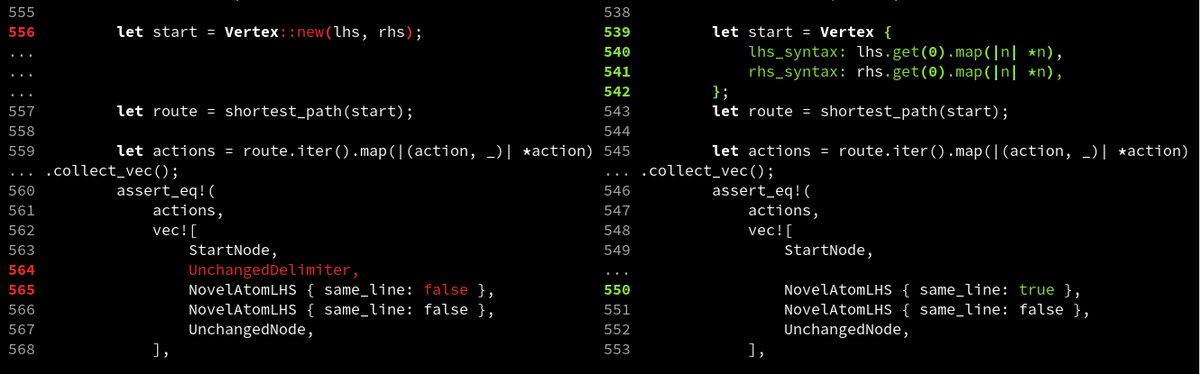
Diffing comments is surprisingly hard. In difftastic, I'm colouring the whole changed comment, but also underlining the changed words.
This works OK, but punctuation is harder to read (see second image) and sometimes there's code in comments (see third image).
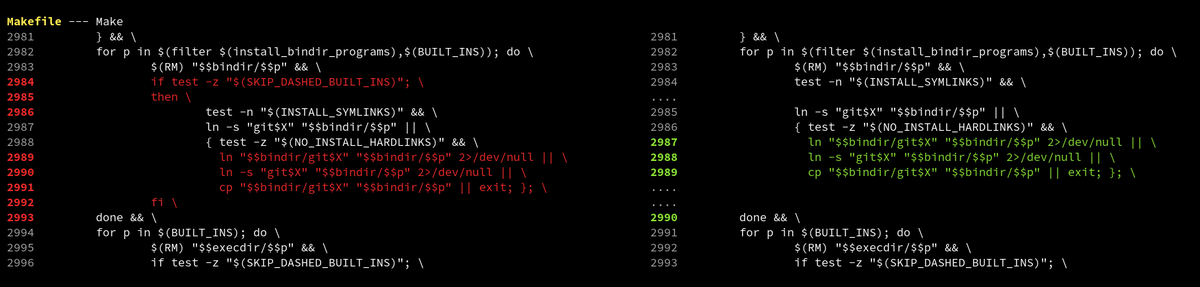
Difftastic now handles tab characters precisely! This sounds like a small thing, but it's crucial when parsing Makefile syntax.
Makefiles look way better now.
(Technically tabs are also syntactically significant inside string literals, and that case is fixed too.)
Most of the gradual type systems I've seen are targetting existing languages: you want to interact with existing libraries that don't have type annotations.
Are there many greenfield languages with gradual types? It's a useful technique in other cases, such as refactoring.
I *love* that GitHub's Ctrl-F search still gives you the option of going back to the browser text search!
It's reasonable to override Ctrl-F in a website, but sometimes you really do want the normal browser tooling.
Programming languages aren't sports teams: you don't have to choose one to root for!
They're more like music genres, you can enjoy more than one.
I avoid language stickers for this reason. I don't want my identity to be "I'm an X programmer".
I've released difftastic 0.40! In this release:
* Faster, more efficient diffing courtesy of QuarticCat :)
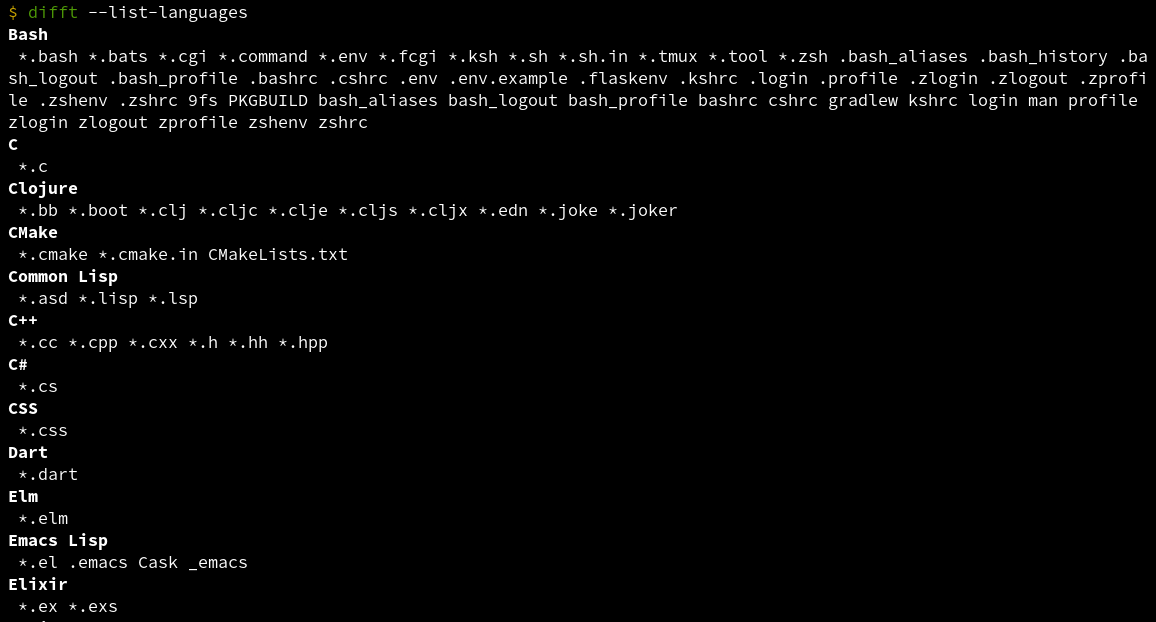
* `--list-languages` is now more helpful
* Better support for older distros
It's weird that some language communities have a thriving wiki, and others simply do not.
It doesn't seem to relate to community size, nor docs quality (e.g. the Emacs manual is great), nor the age of the language.
I don't care what your project's test coverage is, but the fact that you're measuring it is a great sign.
Discoverability on Mastodon is hard: I find myself using hashtags more to discover people.
I'm not aware of any suggestion tools here ("you follow A and B, you might want to follow C").
I'm getting a stream of new followers, which is a great way of finding people, but some users have no toots at all yet.